
Code Roulette: Windows Internal Complexities
Since its inception, the Windows operating system has been a recognizable force within the IT industry and grew increasingly common throughout the 90's and 2000's. Features of the operating system have grown over the last 20 years in response to the changing needs within the industry and shifts in attitudes towards system management, user experience and scale. In the early 2000's Windows dominance was largely driven by a combination of a widely accepted end user experience, flexible server components and a centralized authentication, authorization and configuration solution, Active Directory. Whilst there were some alternatives, the reality was that there was no one stop solution for integration that could compete with Active Directory at scale and as most things are driven by business goals, Active Directory became the central hub of IT operations within a significant portion of the commercial and government markets.
All of these extensions, modules and features for integration add to the complexity of the code base and fundamental operating system components. It is fair to say that Windows internals is a complex subject. A core component of the Windows operating system is the New Technology File System (NTFS) which replaced File Allocation Table (FAT) as the default for managing storage data and volumes. NTFS extensions made it possible to have granular control over access rights through Access Control Lists. NTFS incorporates metadata and tracks these changes to the volume via the file system journaling features and stores these in the NTFS Log ($LogFile)
NTFS allows the recovery of the filesystem through a concept known as "atomic transaction".
If you consider the file system to be a database of tracking file metadata (location, owner etc) as a record then Input/Output operations are referenced as transactions. Some transactions have to complete, and if they don’t, failure will occur. Hopefully, thanks to tracking, if failure does strike then rollback can occur, and you can carry on. You have probably seen these types of transactions occurring when Windows is updating with the message, "Do Not Power Off" as this is essentially performing I/O transactions across the volume. Removing power at this point would halt the transactions mid commit and can sometimes result in total corruption.
So, in quick summary, NTFS has a mechanism for tracking metadata changes for files/directories across a volume and if these changes fail, it can roll back these transactions (changes). Every directory will contain an NTFS attribute referenced as "$i30" which tracks this metadata.
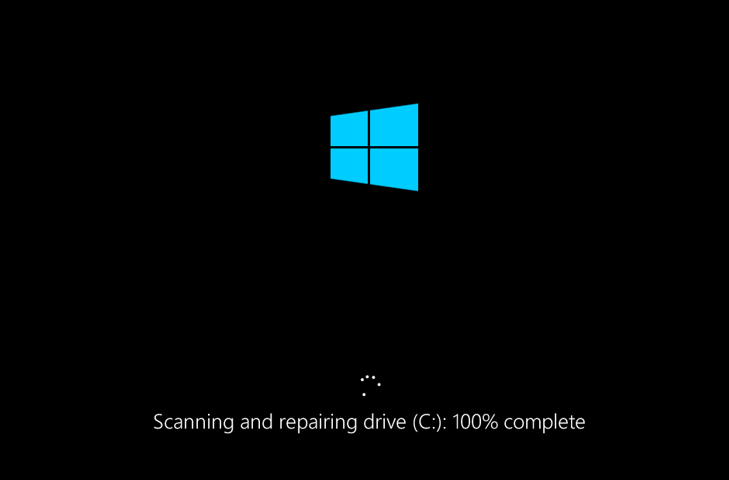
A recent NTFS bug has been disclosed by a researcher called @JonasLyk on Twitter which is related to what happens if you directly call or access the "$i30" attribute within an NTFS volume. He discovered that just accessing this index would result in hard drive corruption messages. You are then forced into the realms of hoping that recovery will be successful, and if not thinking about grabbing your backups. Calling this NTFS attribute causes the machine to restart and perform repair operations. This is due to a flag that is set on the volume indicating that 'chkdsk' needs to run on next start.
The NTFS Bug
WARNING: Running these code examples has a high possibility of corrupting your hard drive. Windows may attempt to repair these issues, but there is no guarantee that this will be successful. We strongly recommend that any of these concepts are explored on a Windows operating systems you are prepared to lose. The ideal solution would be to use a virtual machine with an existing snapshot for recovery. In order to prevent copy and paste, all the code samples are screenshots.
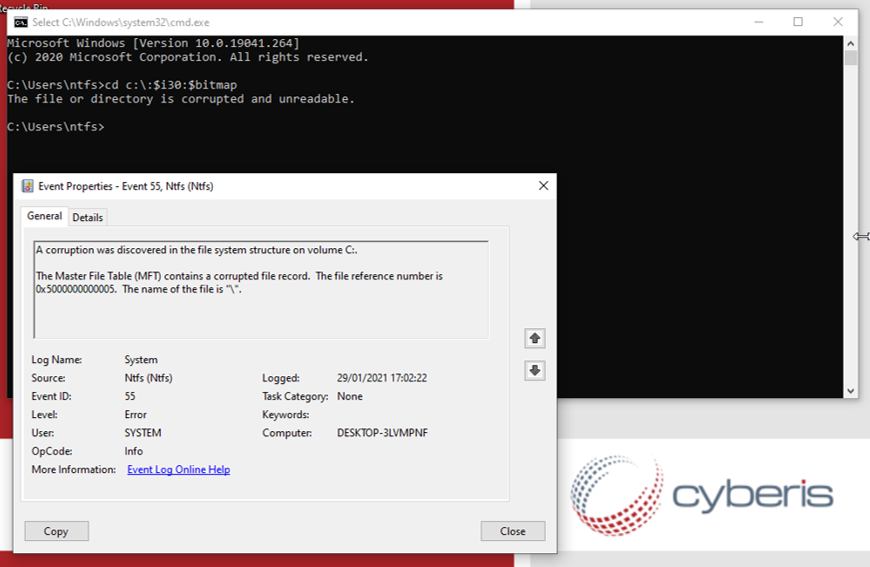
Calling this attribute from a command line results in a hard drive corruption message and then the system restarts and attempts to repair the file system.
Microsoft Operating Systems
Microsoft is good at communicating about the life cycle of its products. A visit to the End-of-Life page will clearly show which versions are currently within this support life cycle and what expectations an end user can have regarding extended support. The state of support is that any server operating system pre-Windows 2012 is now EOL and is an unsupported operating system.
I’ve tested this issue with a version of:
- Windows Server 2003
- Windows 7
- Windows 2008 R2
- Windows 10 - (10.0.19041)
- Window 2016 Core
In the case of Windows Server 2003, my device did not repair successfully, and I had to restore this machine from a snapshot. [Update] Initially, this appeared to relate to the execution via a HTA file, however further investigation showed this could be related to the virtualisation approach and incompatibility with the updated storage drivers that caused volume errors or to do with files corrupted on an 8GB file system boundary. This underlines how reliance of legacy operating systems is a challenge because host updates and software upgrades can directly effect the stability of the guest as software moves on. You are then in the trap where you can't update something because operations break. Systems like this should always be isolated, and upgraded to a supported version as soon as possible.
Whilst the others either ignored the attribute or successfully repaired, the resulting downtime could be an issue for machines, especially servers that provision central resources.
Other reports suggest other Windows variants are vulnerable, but these have not been tested and at present, it only seems to be directly relevant to Windows 10. Where I can replicate this issue, the returned error is "The file or directory is corrupted and unreadable.". This is the response that marks the volume as 'dirty'. There is no official post confirming which older versions may be affected by this issue.
Whilst you can continue to call this attribute on Windows 10 after the first repair, it flags the volume, but doesn't appear to perform an extensive disk repair a second time, reducing the disruption. The real issue is that there are no guarantees that Windows 10 will successfully recover the operating system as there are a number of factors that could affect this. When looking at these types of issues, it should be from the perspective of the disruption they cause.
[Update] I checked to see whether any specific user rights were required and a low privileged user can call the attribute on the Windows 10 machine. I have also tested this with Windows Server 2016 which is considered a companion of Windows 10 based on the initial releases, and Windows Server 2016 did not return the corruption message.
Execution Methods
Some of the advisories related to this issue discuss mechanisms for execution including adding a shortcut file to a directory that triggers this issue. Often, when considering vulnerabilities, we contextualize this around data access. However, we can also consider this from an alternative perspective, 'administrative burden'.
Imagine an attacker has added this as a shortcut link to a central file store within a network that contains legacy and Windows 10 clients. Despite the calls from the security industry to upgrade systems as they are end of life, transition programs are not always timely within a business network, especially if this is large as there is always an associated cost, in terms of time, money, or both. The reality is that organisations still have legacy infrastructure.
Now, we can extend this idea to the administrative burden when a large number of machines open centralized drive shares and, as a part of that listing, automatically parse a malformed link with an "$i30" attribute resulting in hard drive repair messages throughout the estate. Inevitably users will seek help with this sort of message, and this could saturate the IT department with calls. As previously discussed, a collection of conditions can determine whether this repair is successful or not, so this simple action could also result in machines that require manual recovery. This would be hard enough in a dedicated network environment, but machines that call in via VPN connections and have network drives mapped over these connections could also be susceptible, compounding the problem for internal users and IT teams. If you wanted to distract a department by creating a potential software issue for a large user base whilst you pursued other objectives, this could be an effective trigger.
Overwriting paths within shortcut files is also another documented method of triggering this payload. I wanted to see if a common mechanism of delivery employed by attackers could trigger the same error. I wrote a very simple HTA file which essentially replicates the command line example which adds this call to the attribute, with the benefit that there are numerous methods of obfuscation, checks and logic flows that can be added to these applications. The following simple HTA file calls a VBScript object and then passes the command to cmd.exe to execute the call to the NTFS attribute.
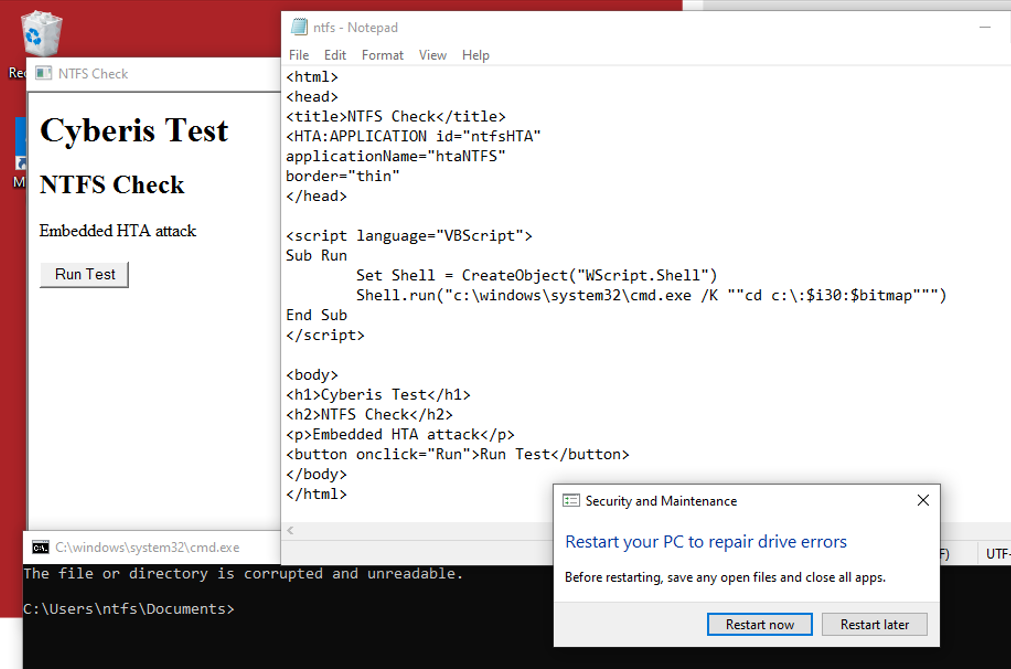
Other mechanisms for execution via trusted binaries could be used to trigger the payload in metadata fields or via building malformed links into zip files. When you consider that the NTFS attribute can be triggered without interaction, for example, just by browsing to a folder location, then this type of attack can create serious challenges for IT departments. This is not because there is a malicious action directly - it may be that the CHKDSK functions will successfully repair the volume and full system operation returns. The wider issue is that this could exceed the level of support an IT department can realistically give and creates a very different challenge to respond to in comparison to an outage of a core server effecting a large user base.
The issues are incoming to the IT department and could originate from internal staff as well as those outside the internal network perimeter making inbound connections. Under those circumstances and at high volume, would incident response playbooks look at this perspective where the trigger for the attack is unknown? There is a physical manifestation of a problem (the hard drive rebooting and performing repair operations) and yet it appears to be some hardware issue across the entire network user base as the same issue is being reported across a variance of Windows systems. Those working in IT have no doubt had a loss of confidence in a system when it appears to demonstrate potential hardware failures. That is difficult to troubleshoot and would certainly bring out the backups.
Detections
Thankfully, Microsoft have been swift to deal with the detection side of this issue and have noted that anytime this condition occurs, this is probably an indicator of malicious intent.
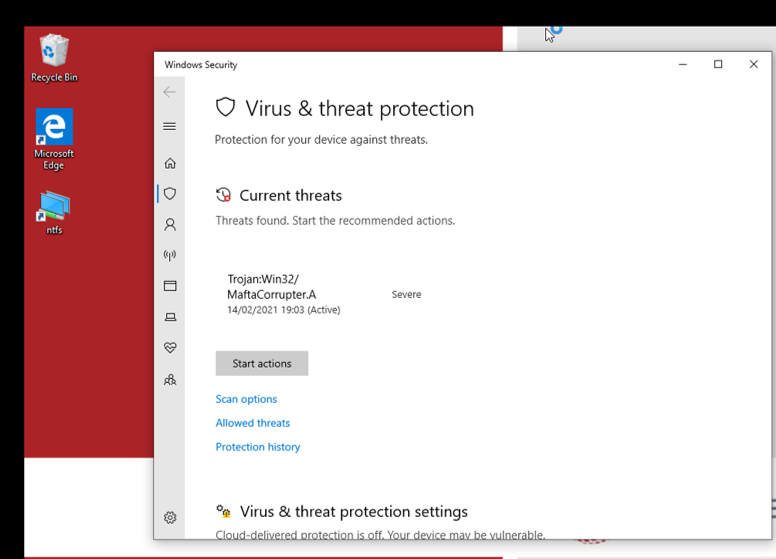
A recent update to Windows Defender now successfully detects this issue as 'Trojan:Win32 MaftaCorrupter.A'. This appears to signature on elements within the path but no extensive obfuscation techniques attempted to bypass these signatures.
During our testing, this was triggered when attempting to create a shortcut link that pointed to the '$i30' path.
Conclusion
There is no doubt that the complexities of the Windows code base and the features that are added into this platform will continue to identify dormant vulnerabilities in the core operating system. The Microsoft eco-system has evolved to allow fast paced remediation of such issues through anti-virus signature updates and regular operating system patching cycles, but this assumes that an organisation has enabled these solutions. It is also very rare for environments to run the latest supported operating system completely across the estate due to legacy dependencies and budget priority. The implications of an attacker adding these types of links into central shares could have considerable effects on internal IT teams if many machines are all simultaneously attempting recovery.
One strategy is to reduce global shares and reduce the attack surface by considering the volume of data that an end user may require. This is more difficult with Distributed File Services as often the collation of shares into one tree is specifically designed to make this easier for users to locate data. Telemetry from user devices is always useful as Defender logs will mark the location of the file. Administrative processes that review and respond to these events and logging could highlight the introduction of these types of links into global shares and provide an early warning, giving time to remove the file, and to investigate how this got there before the help desk phone starts ringing.
[Updated: 2021-11-19]
References
- Twitter: Jonas Lykkegaard - https://twitter.com/jonaslyk
- NTFS Attributes: https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-fscc/c54dec26-1551-4d3a-a0ea-4fa40f848eb3
- End of Life: https://docs.microsoft.com/en-us/lifecycle/products/
Improve your security
Our experienced team will identify and address your most critical information security concerns.